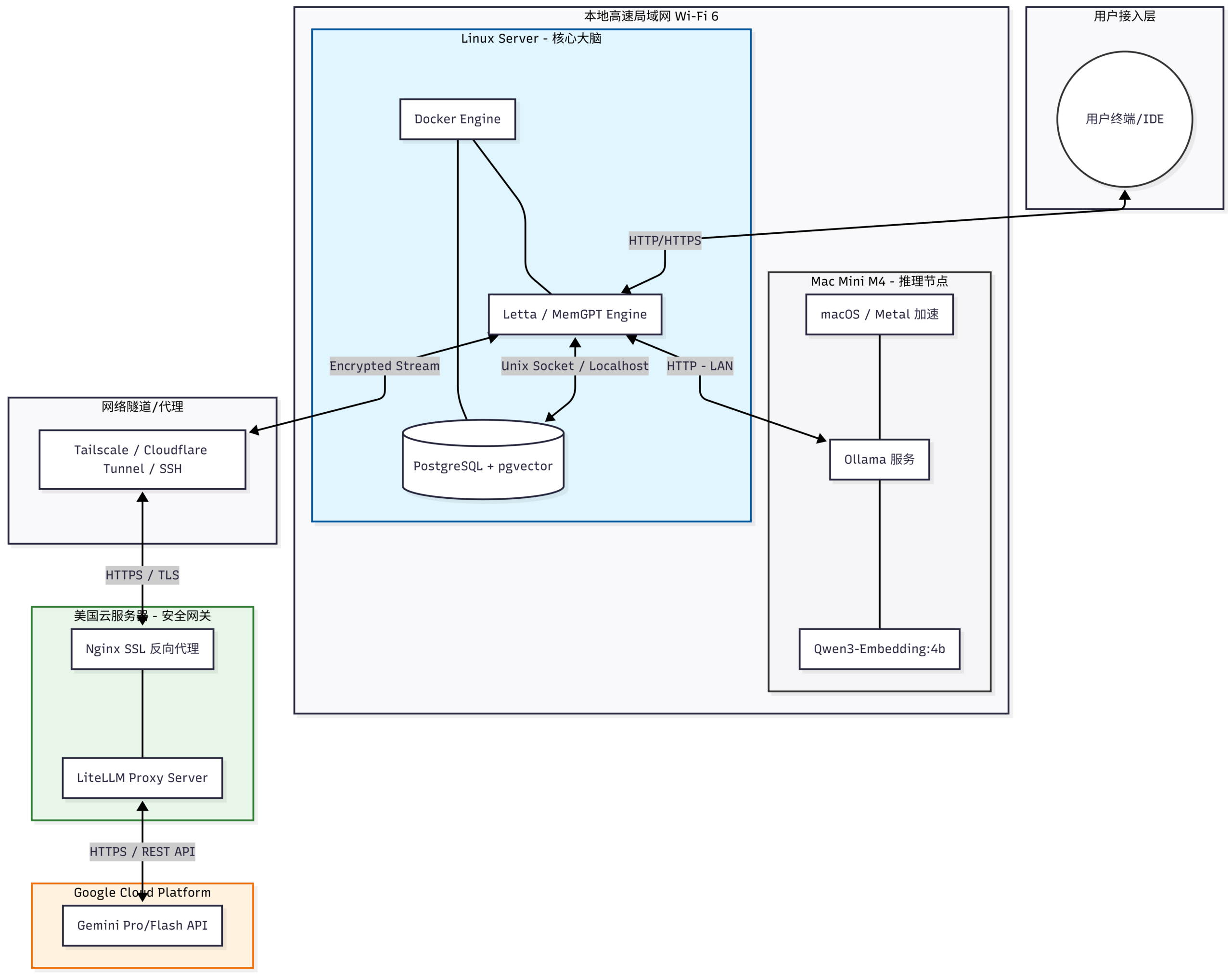
Letta前身为MemGPT,由Embedding model、大模型与向量数据库组成,采用qwen3-embedding:4b + gemini 3.0 flash + postgresql作为组合,部署架构图如下(其中Linux Server使用frp通过腾讯云服务进行反代,此处略过):
Mac Mini部署Ollama + Qwen3-Embedding: 4b模型
官网下载Ollama,下载并运行模型:ollama run qwen3-embedding:4b,
配置模型开机自启动并运行:创建ollama_startup.sh文件并写入:
#!/bin/bash
# 1. 设置环境变量
# 允许局域网访问
launchctl setenv OLLAMA_HOST "0.0.0.0"
# 设置模型永久常驻内存
launchctl setenv OLLAMA_KEEP_ALIVE "-1"
# 2. 启动 Ollama 主程序
# 使用 open -a 确保以 GUI 模式启动(适合 Mac 桌面版 Ollama)
open -a Ollama
# 3. 等待 Ollama 服务完全启动
# 循环检查 11434 端口是否响应,最多等待 30 秒
for i in {1..30}; do
if curl -s http://localhost:11434/api/tags > /dev/null; then
echo "Ollama service is up!"
break
fi
sleep 1
done
# 4. 预热(Warm-up)模型
# 发送一个极小的请求,强制 Ollama 把模型加载进 M4 的 GPU
curl http://localhost:11434/api/embeddings -d '{
"model": "qwen3-embedding:4b",
"prompt": "warmup"
}'创建守护配置文件 ~/Library/LaunchAgents/com.user.ollama_init.plist:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE plist PUBLIC "-//Apple//DTD PLIST 1.0//EN" "http://www.apple.com/DTDs/PropertyList-1.0.dtd">
<plist version="1.0">
<dict>
<key>Label</key>
<string>com.user.ollama_init</string>
<key>ProgramArguments</key>
<array>
<string>/Users/brandon/ollama_startup.sh</string>
</array>
<key>RunAtLoad</key>
<true/>
<key>StandardOutPath</key>
<string>/tmp/ollama_init.stdout.log</string>
<key>StandardErrorPath</key>
<string>/tmp/ollama_init.stderr.log</string>
</dict>
</plist>完成后可以使用postman访问接口进行测试:
POST http://<ip address>:11434/api/embeddings
{
"model": "qwen3-embedding:4b",
"prompt": "Test message"
}自此完成embedding model的部署。
Cloud Server部署LiteLLM
最初在gemini3的推荐下准备使用oneApi,但发现oneApi的docker镜像对云服务器架构的支持不好,因此改为使用newApi,部署后发现功能对于个人使用过于冗杂,因此还是决定采用LiteLLM部署。
由于打算将LiteLLM部署在公网,因此等于将API直接暴露在公网中,如果Master key暴露将导致API被无限制盗刷,因此决定采用https + openssl rand + virtual key + cloudflare代理的组合。
首先配置config.yaml:
model_list:
# 使用通配符,匹配所有以 gemini/ 开头的模型请求
- model_name: "gemini/*"
litellm_params:
model: "gemini/*" # 将星号部分原样传递给 Google API
api_key: "os.environ/GEMINI_API_KEY"
litellm_settings:
drop_params: True # 依然建议开启,自动过滤不支持的参数
set_verbose: False配置docker-compose.yml:
services:
# 1. 数据库服务
db:
image: postgres:16-alpine
container_name: litellm-db
restart: always
environment:
POSTGRES_USER: litellm_admin
POSTGRES_PASSWORD: your_passwd
POSTGRES_DB: litellm_db
volumes:
- ./postgres_data:/var/lib/postgresql/data # 持久化数据库数据
healthcheck:
test: ["CMD-SHELL", "pg_isready -U litellm_admin -d litellm_db"]
interval: 5s
timeout: 5s
retries: 5
# 2. LiteLLM 服务
litellm:
image: ghcr.io/berriai/litellm:main-latest
container_name: litellm
restart: always
ports:
- "4000:4000"
volumes:
- ./config.yaml:/app/config.yaml
environment:
- GEMINI_API_KEY=your_genmini_api_key
- LITELLM_MASTER_KEY=your_master_key
- DATABASE_URL=postgresql://litellm_admin:your_passwd@db:5432/litellm_db
- PROXY_BASE_URL=https://domain.example.com
depends_on:
db:
condition: service_healthy # 确保数据库启动并健康后再启动 litellm
command: [ "--config", "/app/config.yaml", "--port", "4000" ]由于virtual key在ui界面内配置更方便,因此不关闭litellm的ui,且virtual key依赖数据库,因此需要部署postgres数据库。使用virtual key的主要优点在于减少master key的对外暴露,且外部服务即便暴露了virtual key,也不会导致google api的所有权限全部暴露,且virtual key可以设置budget等,安全性相对于直接使用master key要高上许多。
至此LiteLLM完成部署。
Linux Server部署Letta
考虑到后续可能需要进行迁移,因此选择postgresql作为数据库存储,配置docker-compose.yml如下:
services:
letta-db:
image: ankane/pgvector:latest
container_name: letta-db
restart: always
environment:
POSTGRES_USER: ${POSTGRES_USER}
POSTGRES_PASSWORD: ${POSTGRES_PASSWORD}
POSTGRES_DB: ${POSTGRES_DB}
volumes:
- /home/brandon/Services/letta/data:/var/lib/postgresql/data
- /home/brandon/Services/letta/init.sql:/docker-entrypoint-initdb.d/init.sql
healthcheck:
test: ["CMD-SHELL", "pg_isready -U ${POSTGRES_USER} -d ${POSTGRES_DB}"]
interval: 5s
timeout: 5s
retries: 5
letta-server:
image: letta/letta:latest
container_name: letta-server
restart: always
ports:
- "8283:8283"
depends_on:
letta-db:
condition: service_healthy
environment:
- LETTA_PG_URI=${LETTA_PG_URI}
- SECURE=${SECURE}
- OPENAI_API_BASE=${OPENAI_API_BASE}
- OPENAI_API_KEY=${OPENAI_API_KEY}
- OLLAMA_BASE_URL=${OLLAMA_BASE_URL}
volumes:
- /home/brandon/Services/letta/letta_config:/root/.letta其中OPENAI_API_BASE填写LiteLLM的地址(https://litellm.example.com/v1),OPEN_API_KEY填写master key或者virtual key,OLLAMA_BASE_URL填写ollama ip地址(http://192.168.3.12:11434)。
当部署完成后进入web界面发现当前letta统一将前端重定向至https://app.letta.com/,需要在这个页面下连接self-host server。接着在web界面中点击Manage project并在Self-hosted server中连接至letta服务,由于在docker-compose中将SECURE设置为true且没有显示给出passwd,letta会自动生成一个密钥,可以在容器log中查找。将key填入config后即可连接至self-hosted letta backend,接着Create Agent,并在创建出的Agent中选择Model,在Advanced中的Embedding Config中选择Embedding model为本地部署的模型。
至此完成Letta部署。