Memory Network
一.模型意义
Memory Network用于训练类似于机器的阅读理解能力,首先输入文本内容,再对输入的问题进行解答。
二.模型构建
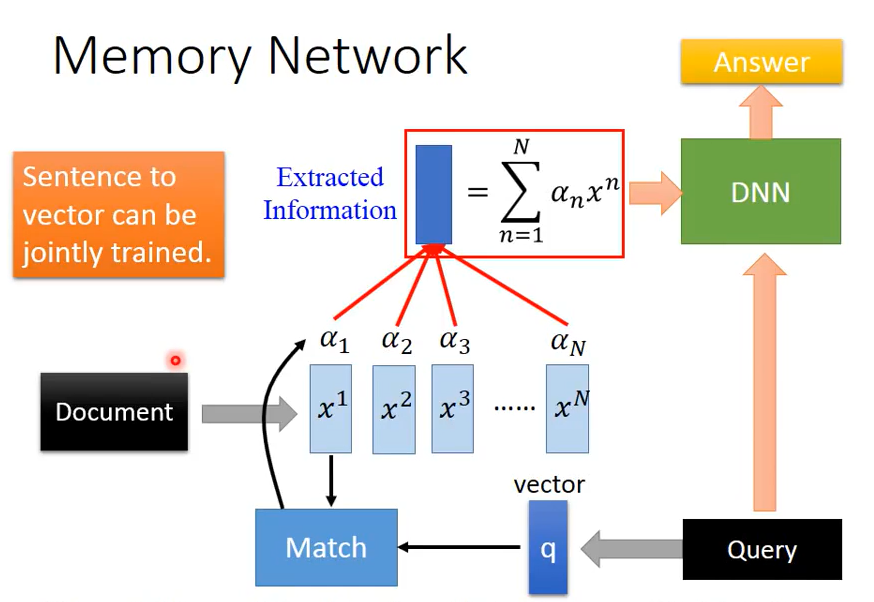
Memory Network实际上为attention model的应用。machine首先将输入的Document中的每一个句子变为一个个vector,再将输入的query同样转化为vector,再将query vector与document vectors经过match函数得到$\alpha_i$,再将$\alpha_i$与$x^i$依次相加求和,并将结果输入DNN从而得到Answer。
其中query vector实际上是对attention model中的初始参数$z^0$的取代,通过match函数控制不同的query对于document不同句子的关注度,从而得到与query相对应的answer。
Neural Turing Machine
一.模型意义
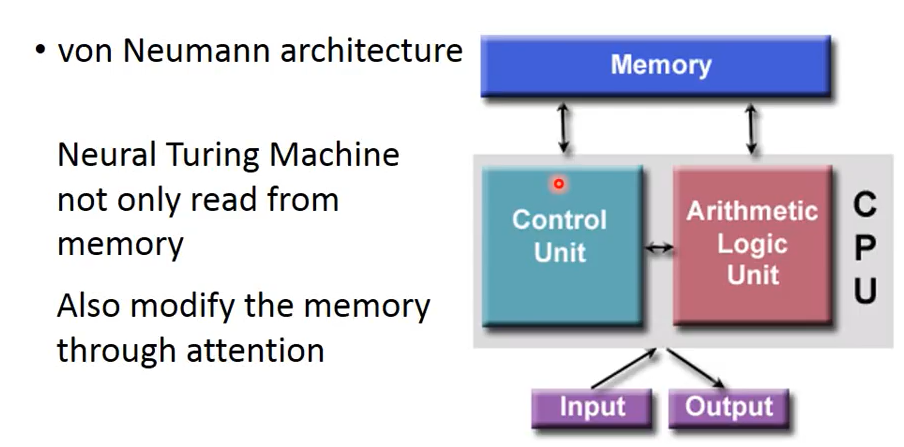
Neural Turing Machine(神经图灵机)不仅从memory里训练出信息,还可以根据match score修改存在memory中的内容,即不仅读memory中的内容还可以改memory中的内容。
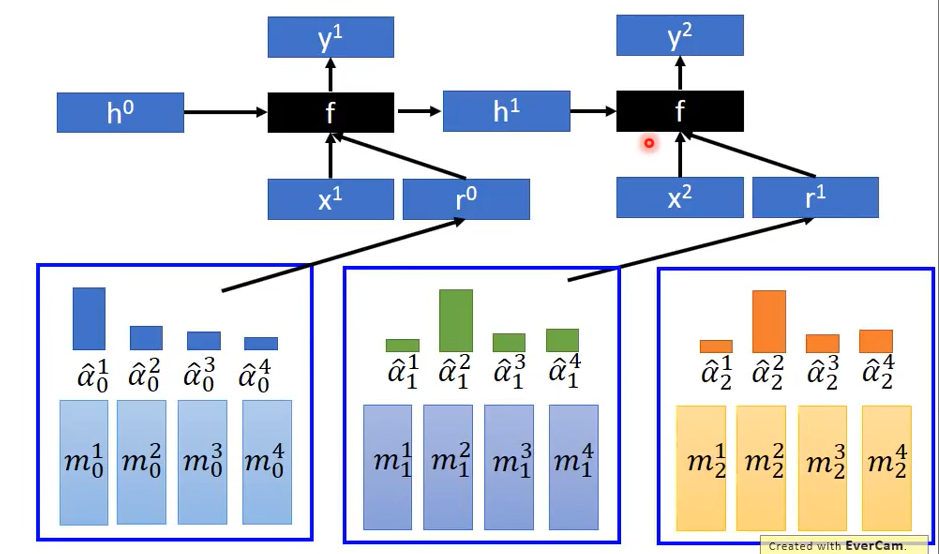
二.模型构建(简化版)
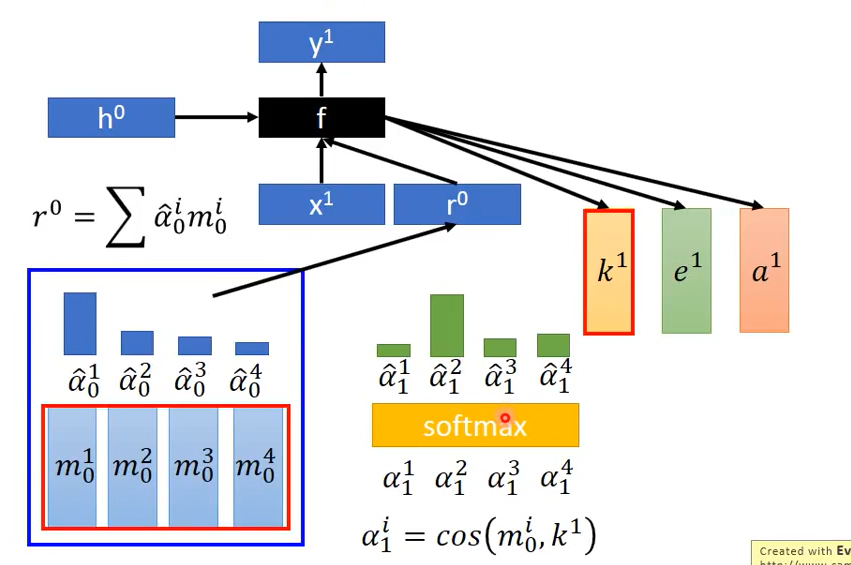
1.首先设置初始memory值$m^i_0$与初始attention值$\hat{\alpha}_0^i$,将各值分别相加求和得到$r^0$,再与第一个时间点的input$x^1$经过自定义函数f从而输出三个vector:$k^1,e^1,a^1$。其中$k^1$的作用在于产生attention,其与$m_0^i$经过 cosine similarity 得到$\alpha_1^i$,再将它们经过softmax从而得到新的$\hat{\alpha}_1^i$
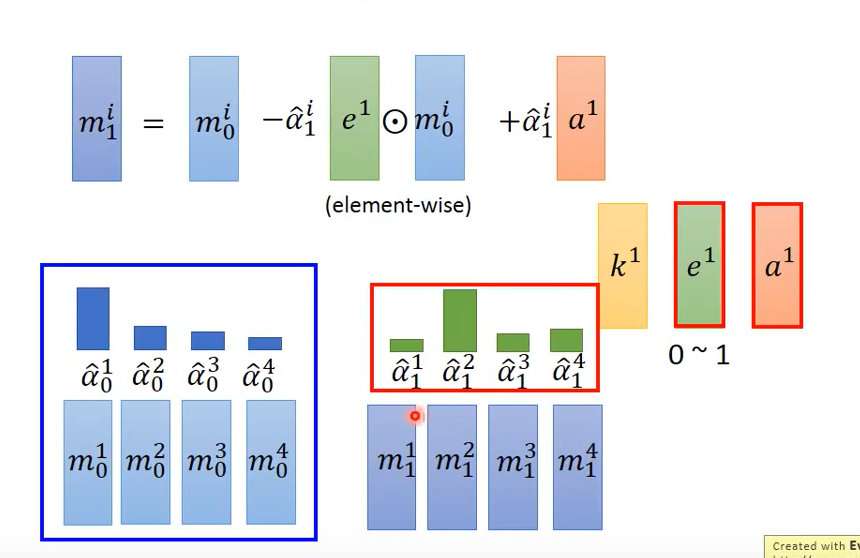
2.修改memory的值,$e^1$的作用为清空memory,$a^1$的作用为将新的值写入memory中。利用如下公式即可对$m_1^i$进行更新
$m_1^i = m_0^i – \hat{\alpha}_1^i e^1 \odot m_0^i + \hat{\alpha}_1^i a^1$
解释:$e^1$的取值在0~1间,由于$\hat{\alpha} _1^i$各值相差很大,假设$\hat{\alpha}_1^2=1$,且$e^1=1$,则式子中的第二项就等于$m_0^2$,第一项与第二项相减即为0($e^1$起到清空作用),此时再加上第三项即更新$m_1^2$值。
3.利用新得到的$\hat{\alpha}_1^i$与$m_1^i$重复上述运算,其中若f函数使用recurrent network则其除了会产生更新memory的vector外还会输出另外的vector $h^1$代表f自己的记忆,再将其输入下一个f中,从而与输入的$x_2,r^1$产生再下一个操控memory的参数
三.Tips for Generation
在Video Captioning(视频描述)训练过程中常会Bad Attention。假设一个视频只有四帧,且使用$\alpha_t^i$表示attention,$w_t$表示每个time产生的word。则在训练过程中由于attention的值不合适,导致每次生成的word并不恰当或重复多次,比如$\alpha_2^2,\alpha_4^2$均得到大值,则第二次time与第四次time生成的word将会相同,从而生成不恰当的句子。

一个简单的处理方式称为Regularization term,即使用如下公式
$\sum_{i}(\tau – \sum_t \alpha_t^i)^2$
其中$\tau$为设定值,用于调整$\alpha_t^i$的数值,该公式含义在于将不同time中的同一个component中的attention相加,若其与$\tau$相差很大则loss将会很大,为降低loss模型将会将同一个component中的attention分散至其他component,从而得到比较好的结果
